A massive DNA search brings viral dark matter into the light.
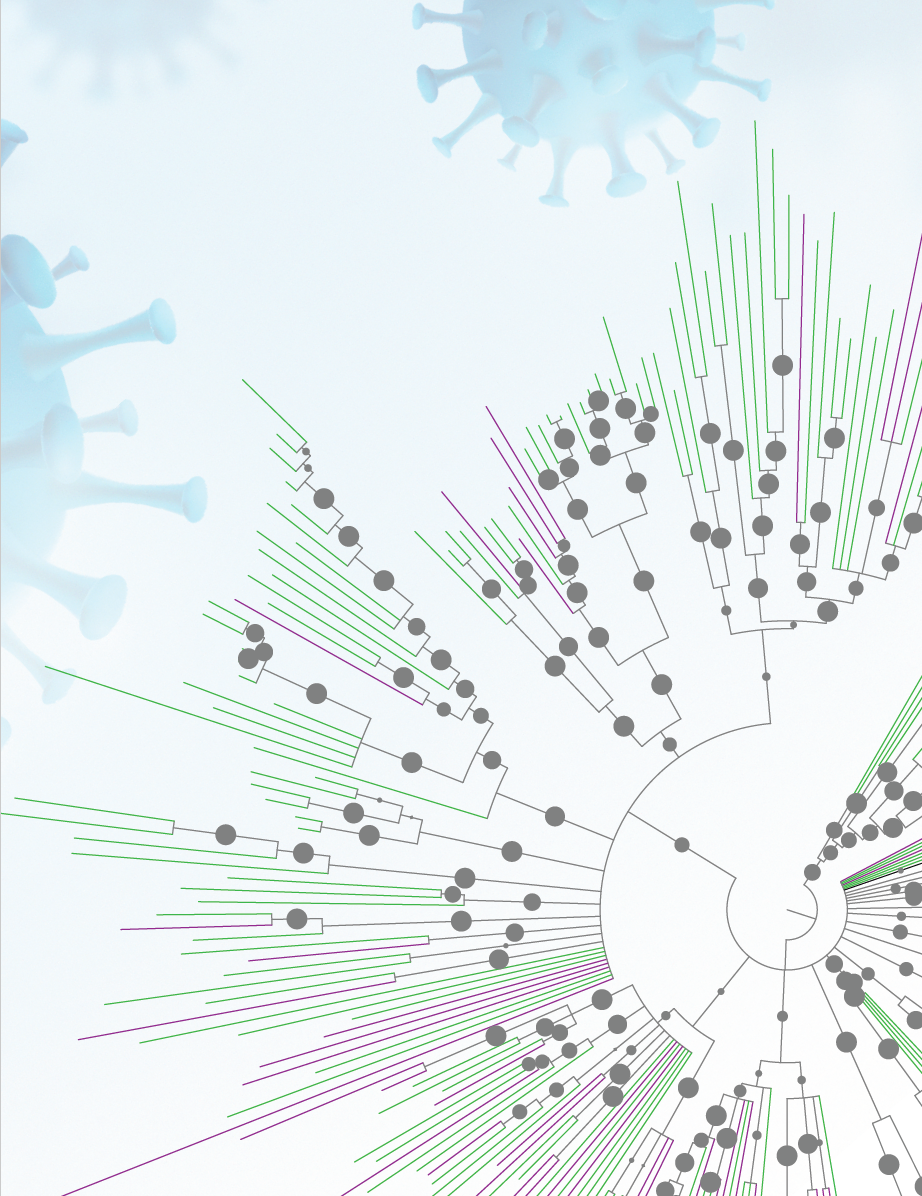
A phylogenetic tree displays relationships between the sequences of capsid proteins, which form the outer shell of some types of viruses. Sequences identified by Christopher Buck, Ph.D., and his team are represented as green lines. Previously known sequences are represented as purple lines. Buck’s tool for analyzing and annotating genomic sequences, called Cenote-Taker, is available at https://cyverse.org/discovery-environment.
Credit: Allen Kane, Scientific Publications, Graphics and Media, Frederick National Laboratory, NCI, NIH; iStock; Michael J. Tisza and Christopher B. Buck
It is thought that there may be hundreds of millions of different kinds of viruses in the world, most of which remain to be discovered. Some of these unknown viruses are likely to play a role in human cancers, but without thorough virus-hunting tactics, it’s easy for them to go undetected.
Researchers led by Christopher Buck, Ph.D., have long been interested in finding viruses that cause cancer, like papilloma- and polyomaviruses. Using a new computational tool that his team developed, he and his colleagues uncovered thousands of previously unknown viruses, which they reported in eLife. Many of the virus sequences they discovered share little genetic makeup with others in the catalog of known viruses. Now researchers will be able to identify these viruses if they are present in tumors or other patient samples, a vital step for exposing their potential contributions to disease.
Buck and research fellow Michael Tisza, Ph.D., set out to find unidentified viruses by scouring vast numbers of genetic sequences, generated by sequencing DNA from a variety of animals, including worms, fish, cows and people. Each sample was a complex mix of DNA from the animals’ own genomes and the genomes of the many microbes and viruses with which they coexist. Although much of the DNA in samples like these is presumed to come from viruses, it is usually impossible to decipher many of the sequences’ exact origins.
Tisza used NIH’s supercomputing resources to search these DNA sequences for elements that encoded virus-like features. To narrow the search, he focused on circular DNA molecules, which are carried by certain viruses but are rare in animals.

The hunt yielded more than 2,500 viral genomes. Many appear to come from viruses that infect bacteria, whose effects on the microbiome can have consequences for human and animal health. Many represent entirely new families of viruses, and some offer unexpected insights into viral evolution. The team tested some of the most unusual suspected viral sequences in the laboratory, using cells to translate the genetic code into proteins. The proteins assembled into particles resembling the outer shells that enclose viruses’ genetic material, supporting the idea that the sequences indeed represent viral genomes.
To ensure that other researchers can recognize the newly discovered viruses, these sequences are now included in GenBank, an essential public database widely used for genetic studies. Furthermore, the researchers say that adding this information about previously absent or poorly represented viral families to the database will make it easier to find additional family members. To facilitate future searches, Buck and Tisza have made their tool for analyzing and annotating genomic sequences, called Cenote-Taker, freely available to the research community.
Buck and Tisza say that even after their discovery, the list of known viruses likely includes only a tiny fraction of those that exist in the world. They have already expanded their search and unearthed evidence of new viruses within additional sets of DNA sequences, including viruses that may be relevant to cancer.