
Mikhail Kolmogorov, Ph.D.
- Center for Cancer Research
- National Cancer Institute
- Building 41, Room A100C
- Bethesda, MD 20892
- 240-858-3169
- mikhail.kolmogorov@nih.gov
RESEARCH SUMMARY
The focus of Dr. Kolmogorov’s research is computational genomics, with particular interest in cancer. The Kolmogorov lab develops new algorithms and tools that take advantage of new genomic technologies (such as long-read sequencing or Hi-C) to understand how genomic mutations and rearrangements affect cancer evolution and treatment response.
Areas of Expertise
Mikhail Kolmogorov, Ph.D.
Research
New sequencing technologies and algorithms to study cryptic variation in cancer genomes
Cancer is a disease of the genome. Most cancers are driven by somatic mutations, such as single nucleotide variations (SNVs) that can alter protein sequence and function. Another hallmark of cancer is structural variation (SV), a process that can insert, delete or rearrange large chromosomal fragments. SVs vary greatly in size and complexity: from local oncogene amplifications to catastrophic events that shuffle megabase-scale fragments from one or multiple chromosomes.
Recent analysis of 2,658 tumors by the Pan-Cancer Analysis of Whole Genomes project showed that ~50% of cancer driver mutations are explained by SVs. Despite that, somatic SVs in cancer remain understudied because of technological and methodological challenges. Most current cancer genomics projects rely on short-read sequencing data, which systematically miss certain classes of somatic SVs and often produce many false-positive calls.
Our lab is developing new computational approaches that utilize novel sequencing technologies (such as long-read sequencing or chromatin conformation capture) to better understand the prevalence and role of SV in cancer. In collaboration with other NIH and extramural investigators, we apply these new methods to various cancer types and patient cohorts. We also aim to improve scalability and democratize the cost of long-read sequencing projects, paving the road towards the complete variational landscape of the human genome and microbiome.
Current research highlights
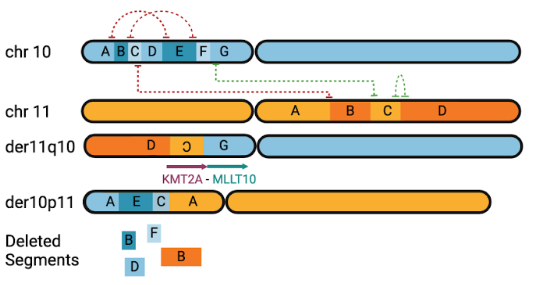
New open-source tools for characterization of complex somatic SVs and CNVs using long reads. Despite the recent successes of long-read genomics (including the methods developed in our group), most current popular approaches were not designed to handle the complexity of a cancer genome. Our lab is developing several new long-read tools to address this. Severus, a breakpoint graph-based algorithm for somatic SV calling that supports matching tumor/normal analysis, can characterize complex multi-break rearrangements, and produces phased calls. Another tool, Wakhan, for haplotype-specific copy number variant (CNV) calling, designed to explore large chromosomal aberrations - such as aneuploidy - and at the same time sensitive to small focal amplifications.

Long-read genome assembly of heterogeneous human microbiomes. Bacterial species in microbial communities are often represented by mixtures of strains, distinguished by small variations in their genomes. Short-read approaches can be used to detect small-scale variation between strains but fail to phase these variants into contiguous haplotypes. We have developed Strainy, for strain-level metagenome assembly and phasing from long-read metagenomic sequencing. Strainy takes a de novo metagenomic assembly as input and identifies strain variants, which are then phased and assembled into contiguous haplotypes.
Scalable methods for population-scale long-read sequencing. Despite the advances of long-read technologies, cost and scalability have remained prohibitive barriers to the use of in population-scale studies. We are developing new methods and engaging with various groups and consortia to ultimately enable long-read analysis of thousands of samples. This will pave the road towards understanding of the population-scale structural diversity of the human genome. For example, in collaboration with NIH CARD, we developed the Napu pipeline with the ultimate goal of sequencing and analyzing 4000+ human brain genomes.
Publications
- Bibliography Link
- View Dr. Kolmogorov's full Google Scholar bibliography.
Assembly of long, error-prone reads using repeat graphs
Biography

Mikhail Kolmogorov, Ph.D.
Mikhail is currently a Stadtman investigator at the National Cancer Institute, where he leads a group focusing on computational and cancer genomics. Prior to that, Mikhail was a postdoctoral fellow at the UC Santa Cruz, supervised by Dr. Benedict Paten. Mikhail completed his Ph.D. in September 2019 in Computer Science from UC San Diego, under the mentorship of Dr. Pavel Pevzner. Mikhail received his M.S. in bioinformatics from St. Petersburg Academic University, Russia.
Job Vacancies
We have no open positions in our group at this time, please check back later.
To see all available positions at CCR, take a look at our Careers page. You can also subscribe to receive CCR's latest job and training opportunities in your inbox.
Team



News
Learn more about CCR research advances, new discoveries and more
on our news section.
Resources
Our Software
Severus is a somatic structural variation (SV) caller for long reads (both PacBio and ONT). It is designed for matching tumor/normal analysis, supports multiple tumor samples, and produces accurate and complete somatic and germline calls. Severus takes advantage of long-read phasing and uses the breakpoint graph framework to model complex chromosomal rearrangements.
A tool to analyze haplotype-specific chromosome-scale somatic copy number aberrations and aneuploidy using long reads (Oxford Nanopore, PacBio). Wakhan takes long-read alignment and phased heterozygous variants as input, and first uses extends the phased blocks, taking advantage of the CNA differences between the haplotypes. Wakhan then generates inetractive haplotype-specific coverage plots.
Strainy is a tool for phasing and assembly of bacterial strains from long-read sequencing data (either Oxford Nanopore or PacBio). Given a reference (or collapsed de novo assembly) and set of aligned reads as input, Strainy produces multi-allelic phasing, individual strain haplotypes and strain-specific variant calls.
Flye is a de novo assembler for single molecule sequencing reads, such as those produced by PacBio and Oxford Nanopore Technologies. It is designed for a wide range of datasets, from small bacterial projects to large mammalian-scale assemblies. Flye also has a special mode for metagenome assembly.